
Une brève histoire du DOM (jusqu'à React et Redux)
On va parler aujourd'hui des techniques récentes de programmation web, en faisant un petit retour en arrière pour expliquer brièvement le cheminement qui a eu lieu depuis le Paléolithique jusqu'à React. Cette présentation a eu lieu à l'avant-dernier colloque Anybox, et l'objectif était de présenter avant tout l'assemblage React + Redux, et d'expliquer pourquoi jQuery est devenu inutile.
L'époque du HTML statique
Le Paléolithique dont je parlais c'est l'époque du HTML statique généré côté serveur. Le navigateur fait une requête au serveur qui se débrouille pour lancer un programme et renvoyer une page HTML. L'utilisateur peut cliquer sur un lien dans cette page, ça envoie une requête au serveur, qui renvoie de nouveau une page HTML complète. Chaque page HTML est analysée par le navigateur, qui construit dans sa mémoire une représentation objet arborescente et standardisée de la page, qu'on appelle le DOM. L'objet racine est le document, qui contient un objet html, qui contient un objet head et un objet body, qui lui-même contient d'autres objets composant la page web, par exemple des div.
Le Paléolithique a la vie dure, parce que le HTML généré côté serveur est encore indispensable aujourd'hui. D'abord pour des raisons d'indexation par les moteurs de recherche, mais aussi pour diminuer le temps de chargement de la première page et éviter de surcharger le terminal client, qui se réduit souvent à un simple smartphone bas de gamme.
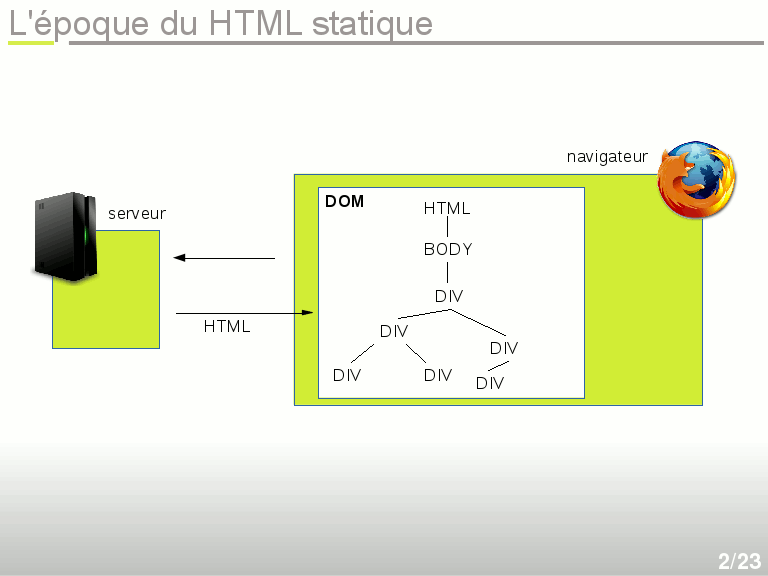
L'époque DHTML
Je fais abstraction de l'abominable époque du Flash, qui fut une catastrophe à plusieurs niveaux : lourd, lent, mal sécurisé, non standard, non transparent, et j'en passe. Heureusement cette époque est terminée. En parallèle du Flash, de vaillants développeurs s'escrimaient à incorporer un peu de Dynamisme et d'animations dans les pages web grâce au langage Javascript, considéré à l'époque par les puristes comme le mal absolu juste derrière le Flash. Ces pages dynamiques, comprenez avec des éléments mobiles ou des comportements avancés, ont été appelées DHTML, pour Dynamic HTML. Comme le Javascript donne facilement accès au DOM, il était alors possible de manipuler ce DOM, d'ajouter ou supprimer des éléments, par exemple des blocs div, mais aussi d'apporter des modifications au style de la page, le CSS.
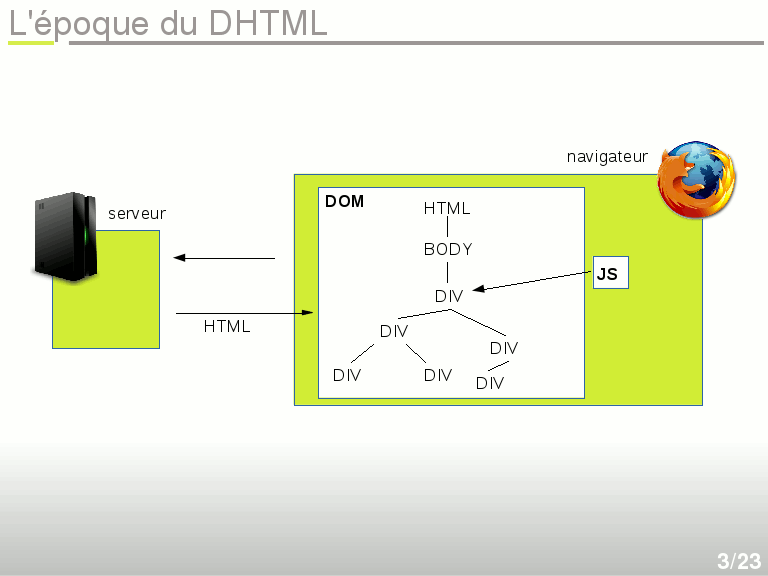
L'époque jQuery
À force de manipuler le DOM, il a été utile de mutualiser des composants permettant ces manipulations. On a donc vu apparaître des bibliothèques (par pitié ne dites pas « librairie »), et notamment jQuery, dont le principal intérêt est de faciliter la sélection d'un objet dans le DOM, grâce à un langage de requête vaguement similaire à celui de CSS. jQuery étant modulaire, on a vu fleurir un nombre impressionnant de plugins et jQuery a fini par s'imposer comme la référence par défaut pour tout faire, y compris des morceaux d'interface graphique, des animations, des validations de formulaire, etc. De nombreuses autres bibliothèques étaient dans la course, comme Mootools, YUI de Yahoo, etc.
Le principe de toutes ces bibliothèques est toujours le même : accéder au DOM pour le modifier, l'enrichir ou rendre dynamique une page web. Là où ça commence à se compliquer, c'est que les composants Javascript eux-mêmes ont commencé à interagir ensemble, envoyer des requêtes au serveur grâce à l'objet XHR. Par exemple un bouton peut ajouter un bloc div, envoyer une requête au serveur, faire apparaître une animation GIF pour indiquer à l'utilisateur que le contenu est en train de se charger, puis notifier un autre élément de l'interface qui lui-même va se mettre à jour et notifier l'utilisateur, etc. Comme tout ceci fonctionne avec des appels asynchrones basés sur des événements, ça devient parfois difficile de comprendre les échanges qui ont lieu, ainsi que de les débugger. Soit dit en passant, ça augmente aussi les chances d'avoir des failles de sécurité.
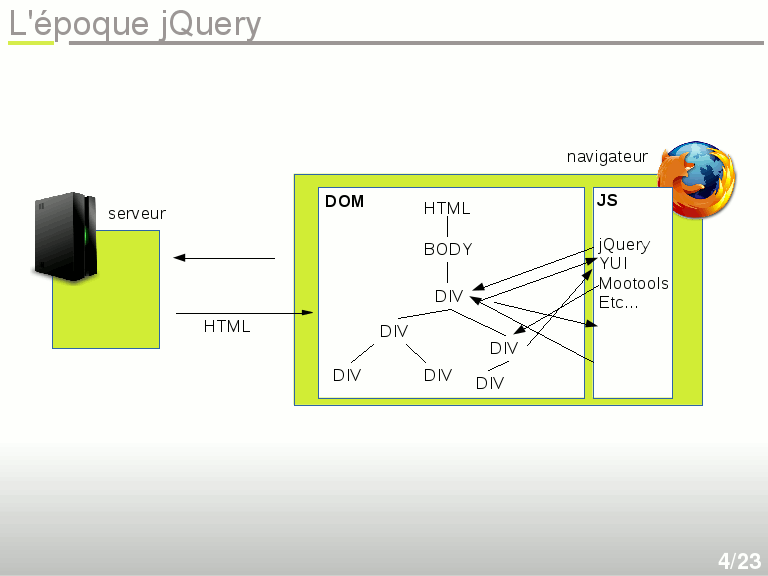
« Euh mais attends, il a bien dit l'EPOQUE jQuery, non ? Est-ce qu'il veut dire par là que jQuery c'est du passé ?? »
En fait Oui. Mais continuez à lire. jQuery est toujours très largement utilisé aujourd'hui, mais c'est juste une question de temps et d'inertie. Aujourd'hui vous n'en avez plus du tout besoin. La vraie révolution commence 2 slides plus loin.
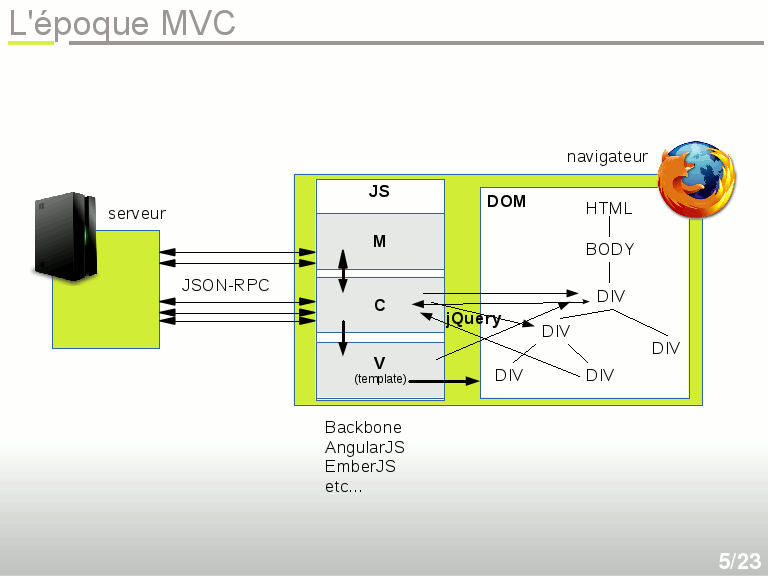
L'époque MVC
À force d'empiler du Javascript dans tous les sens, et comme les pages web ont fini par être entièrement générées par le Javascript, on s'est dit : TIENS ! Pourquoi ne pas ré-utiliser la même architecture que sur le serveur, et découper proprement le code Javascript en trois tiers pour avoir des Modèles, des Vues et des Contrôleurs ? Avoir un MVC côté serveur n'était pas suffisant, il fallait maintenant en gérer deux ! L'un des pionniers de cette architecture est BackboneJS, suivi rapidement par une horde d'autres frameworks plus ou moins complets, notamment AngularJS ou EmberJS. Assez souvent dans les frameworks MVC en Javascript jQuery est encore utilisé, puisqu'on continue à manipuler le DOM. La différence est que le DOM est généré proprement par un langage de templating plutôt que d'être bidouillé à la main.
Donc pour résumer, on a un ensemble de modèles qui peuvent se synchroniser (ou pas) avec les modèles côté serveur. Le contrôleur, avec sa place centrale, peut dialoguer avec l'utilisateur, le serveur et le modèle, pour finalement transmettre des données à un langage de templating afin de générer une page complète. La page elle-même peut envoyer des événements qui seront interceptés par le contrôleur, qui pourra de nouveau réagir et modifier les modèles, ou dialoguer avec le serveur. Parfois il y a des automatismes, comme des synchronisations de l'interface en fonction du modèle, avec une bonne dose de magie apparente.
Tout ça est un peu plus propre, mais au bout du compte ça reste souvent complexe à comprendre et à débugger, car il persiste de nombreux échanges asynchrones, qui peuvent impliquer tous les niveaux de l'architecture, et ceux qui se sont essayé à développer des applications complexes savent que ça devient vite ingérable. En outre, si les modèles côté client et côté serveur sont les mêmes, ça fait une duplication de code malvenue et un temps de développement et de debug plus long.
Petite parenthèse, le framework Meteor offre une solution élégante à ce problème : on n"écrit les modèles qu'une seule fois et ceux-ci sont valables aussi bien côté serveur que côté Client. Ceci n'est possible que parce que Javascript est utilisé aussi côté serveur.
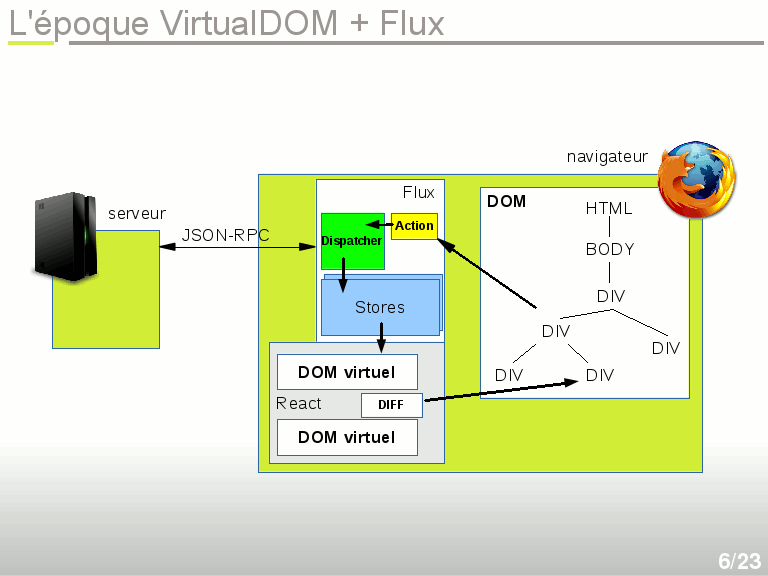
L'époque Virtual DOM + Flux
La voilà la vraie révolution (en attendant la prochaine) : c'est React !
Elle provient de Facebook, et l'idée maitresse de cette bibliothèque est d'offrir ce fameux système de DOM virtuel. En réalité la vraie révolution n'est pas React en soi mais plutôt le DOM virtuel, qui a été implémenté par d'autres bibliothèques. Un DOM virtuel est une représentation du DOM en Javascript. Au lieu de générer le DOM lui-même comme avec un langage de templating, c'est à dire au lieu de dialoguer avec les API du navigateur pour construire le DOM, on ne génère qu'une arborescence d'objets Javascript en mémoire. Dès qu'il se passe la moindre chose, une interaction avec l'utilisateur, un dialogue avec le serveur, alors on régénère TOUTE cette arborescence d'objets, c'est à dire toute la page web virtuelle. Au premier affichage, le DOM virtuel est transformé en DOM réel. Ensuite la bibliothèque React conserve au moins deux versions de l'arborescence, celle qui correspond au DOM réel et la nouvelle version qu'on veut afficher. Puis il calcule la différence entre les deux versions et interagit lui-même avec le DOM pour trouver la façon minimale de le modifier pour obtenir la page souhaitée. Manipuler du Javascript étant beaucoup plus rapide que de manipuler le DOM, il est même possible de régénérer cette arborescence plusieurs dizaines de fois par seconde. On peut donc en profiter pour faire des animations. Et si jamais des lenteurs se font sentir, on peut court-circuiter certaines parties de l'arborescence dans la régénération.
Conclusion : On ne touche PLUS JAMAIS le DOM soi-même !
Corrolaire → jQuery est devenu inutile...
C'est bien joli tout ça, mais là on ne parle que d'affichage. Comment gère t-on notre modèle de données ?
Facebook a réfléchi non sans mal à construire une architecture adaptée à React, et l'a appelée Flux. Initialement ça n'était pas du code, mais juste une architecture. L'idée de Flux consiste plus ou moins à renommer les Modèles en Store, les Contrôleurs en Dispatchers et, surtout, à ne déplacer les données que dans un seul sens : Action → Dispatcher → Store → DOM Virtuel → Action. Cette simplification du flux de traitement de données n'est possible que parce que React permet de tout régénérer à chaque action. On pourrait le faire avec le DOM mais ce serait horriblement lent.
Résumons donc la chose : un événement lié à l'interface graphique ou à une interaction avec le serveur génère un événement à partir duquel on crée une Action, qui n'est rien d'autre qu'un simple objet Javascript décrivant ce qui vient de se passer. Cette action est envoyée à un Dispatcher, qui s'occupe d'aller choisir et modifier le bon Store, c'est à dire le modèle de données, et ce Store est utilisé pour régénérer entièrement le DOM virtuel. Puis le diff avec l'ancien DOM virtuel a lieu, et React modifie le DOM réel en conséquence. Le gros avantage est qu'on peut suivre de bout en bout ce qui se passe de manière séquentielle, sans trop se perdre dans des traitements asynchrones dont on ne maitrise pas l'ordre.
Un autre intérêt est qu'on obtient facilement de la modularité : un module peut apporter son lot d'Actions et de Stores, et s'insérer dans le traitement global sans toucher au reste.
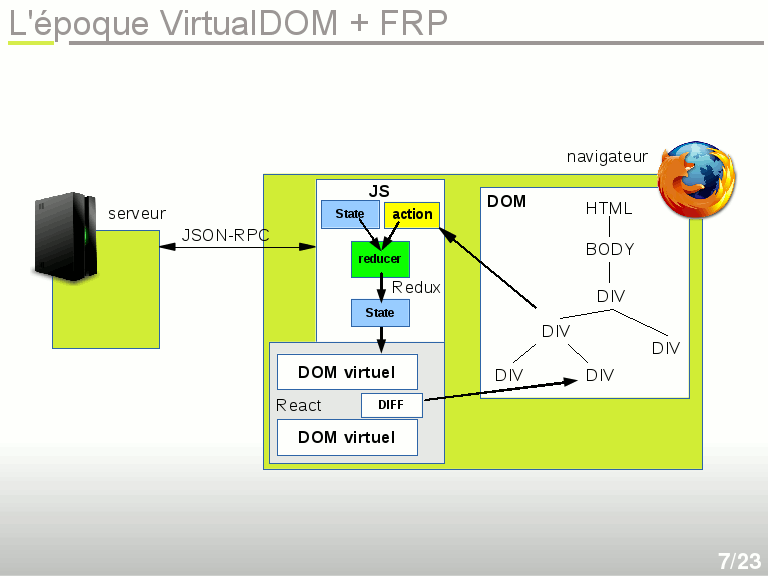
L'époque VirtualDOM + Functional Reactive Programming
En observant Flux et ses implémentations, on se rend compte que les Stores et les Dispatchers font beaucoup de choses inutiles. Au final ça ressemble parfois à ce qui se passe dans un framework MVC. C'est là que Redux entre en scène, et simplifie Flux à l'extrême grâce à des notions de programmation fonctionnelle, très proches de ce qu'on retrouve dans Elm :
- le Store s'appelle plutôt State et surtout il est immuable. On ne le modifie jamais, on en recrée un nouveau.
- le State est l'unique source de vérité sur l'état actuel de la TOTALITÉ de l'application côté front.
- le Dispatcher s'appelle plutôt Reducer, et devient une simple fonction qui utilise une action et un State pour fournir un nouveau State. C'est donc une fonction PURE, c'est à dire sans aucun effet de bord : les mêmes entrées produisent les mêmes sorties.
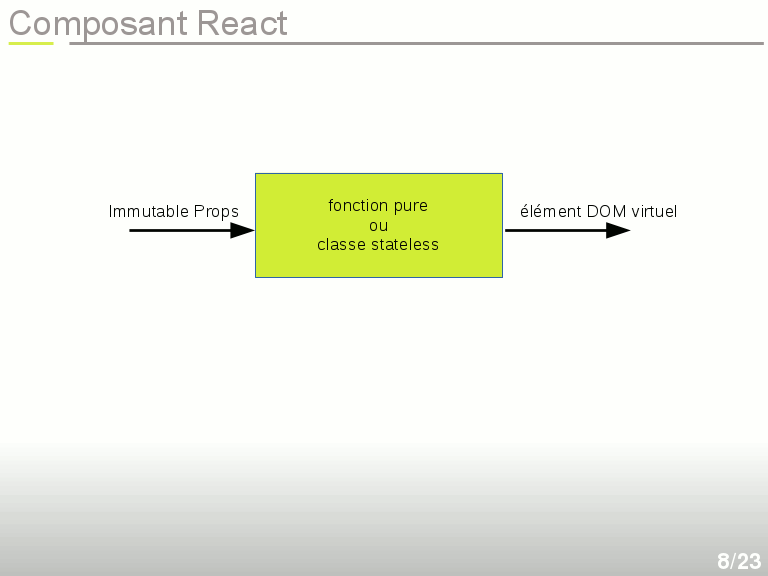
Un peu plus de détails !
Tout ceci mérite un peu plus d'explications. Commençons par un composant React. Un composant React est un objet Javascript, souvent une fonction pure, qui prend en entrée des paramètres immuables, qu'on appelle props, et qui donne en sortie un objet correspondant à un morceau de DOM virtuel. Par exemple un formulaire web, un champ, un menu ou juste un div. Donc on peut très bien créer un composant <form>, un <field>, un <menu>, un <div>, etc. Tous ces composants sont des objets Javascript, donc la page web n'est jamais décrite par un template, mais par une arborescence d'objets.
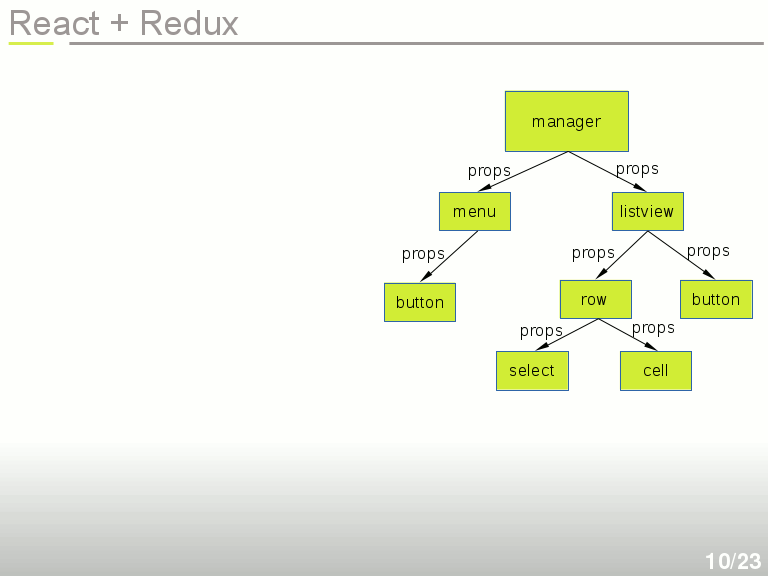
L'intérêt de ce système est qu'on peut faire de la composition : un composant React correspondant à un formulaire peut utiliser plusieurs sous-composants React correspondant aux champs du formulaire, qui peuvent eux-même utiliser des sous-sous-composants par exemple pour la validation des champs. À la fin on obtient le DOM virtuel complet, par assemblage de composants. On n'est pas non plus obligé d'utiliser React pour la totalité de la page, il peut être utilisé juste pour une section donnée.

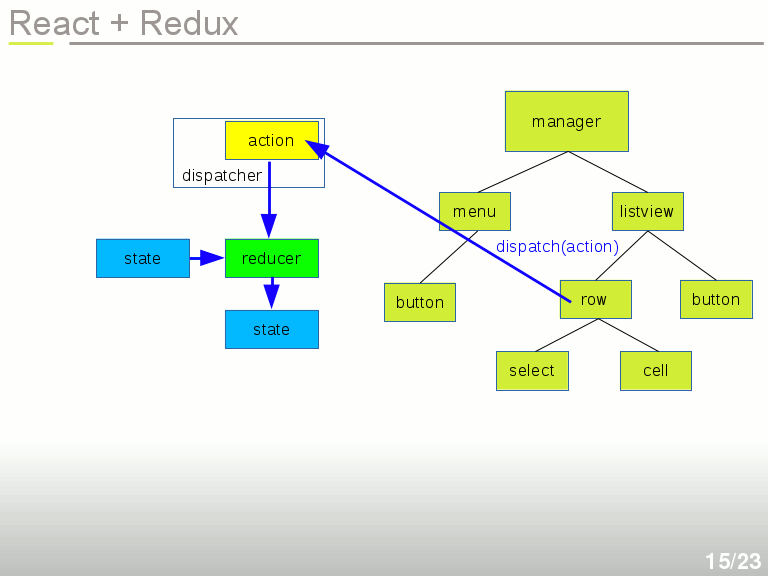
Imaginons maintenant une application affichant une liste. Un objet Manager utilise un objet Menu et un objet Listview, qui elle-même contient une liste de Rows, qui chacune contient une cellule et une case à cocher pour la sélection de la ligne.
On clique sur la ligne, ce qui crée un événement intercepté par le composant React, et on génére un objet Action, qui contient le numéro de la ligne et le nom de l'événement associé. Idéalement on fait ça en remontant (grâce aux props qui peuvent transmettre un callback) jusqu'à un composant Manager assez haut dans l'arborescence, afin que tous les sous-composants soient des fonctions pures.
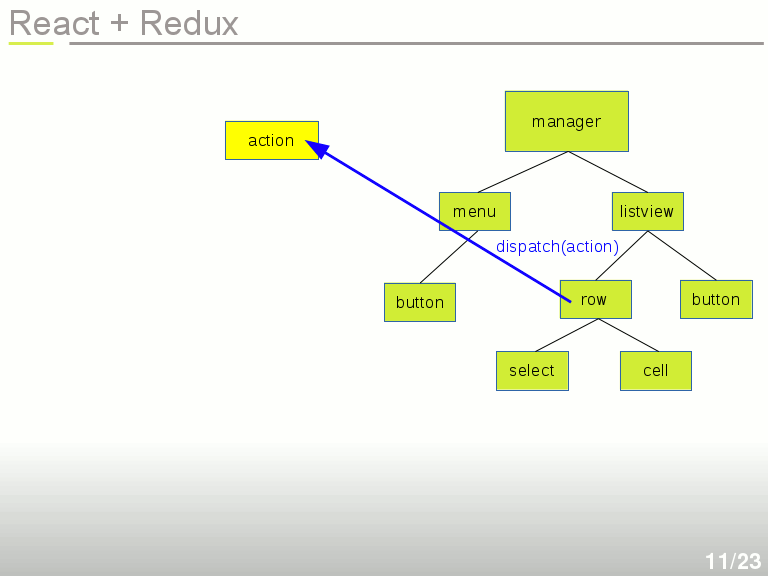
Cette action est retransmise à une simple fonction dispatch(). Le dispatcher est une fonction fournie par Redux. L'appel à dispatch() se fait tout simplement dans le callback de l'événement.
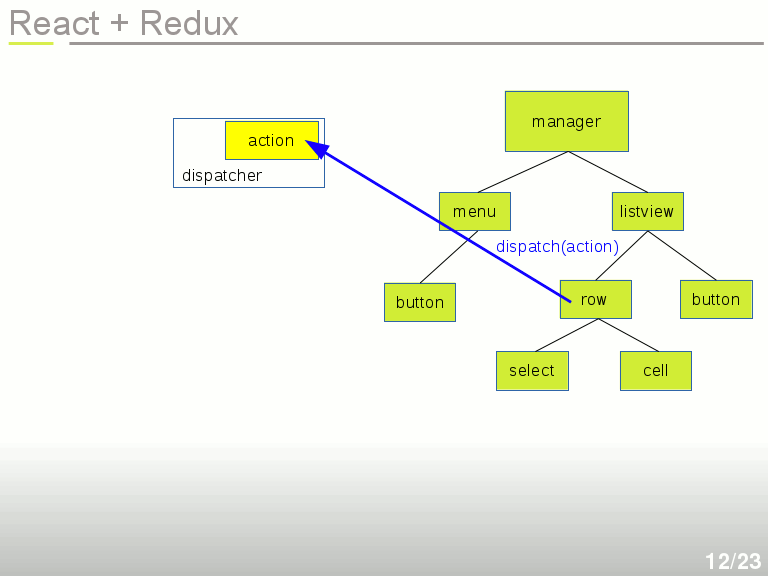
C'est à ce moment que le State intervient.
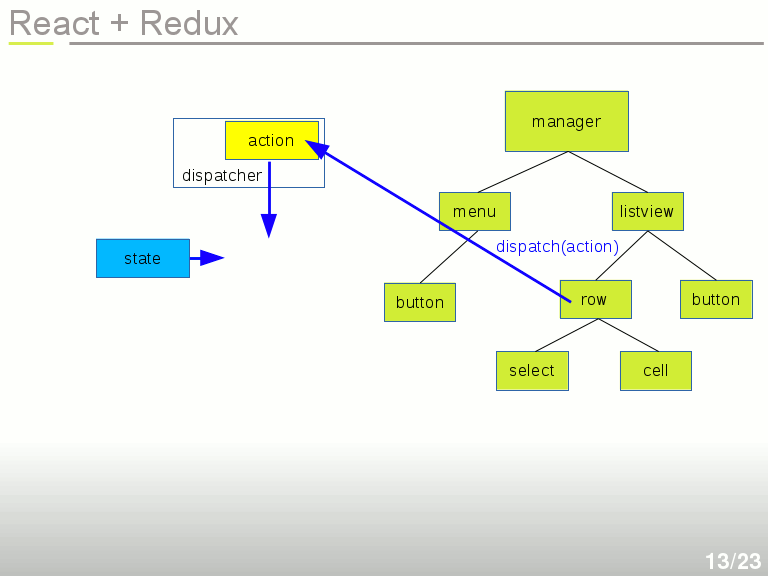
L'Action et le State sont tous les deux envoyés à un Reducteur. C'est à vous d'écrire le réducteur. Un réducteur applique une transformation similaire à un reduce : State + Action → nouveau State
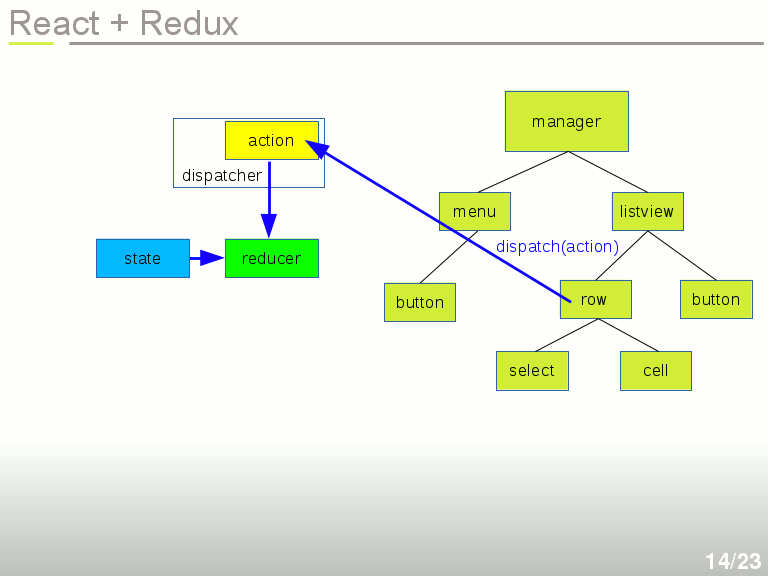
Le Réducteur est donc une fonction souvent simplissime qui consiste à prendre une Action et un état (State) de votre application, puis calculer un nouvel état. Il faut prendre garde à ne pas modifier le State, mais bien à en créer un nouveau par exemple par duplication. Si des sous-objets du State n'ont pas changé, vous pouvez les inclure dans le nouveau State. Ça permet de faire de la comparaison légère en ne tenant compte que des références des sous-objets et non de leur contenu.
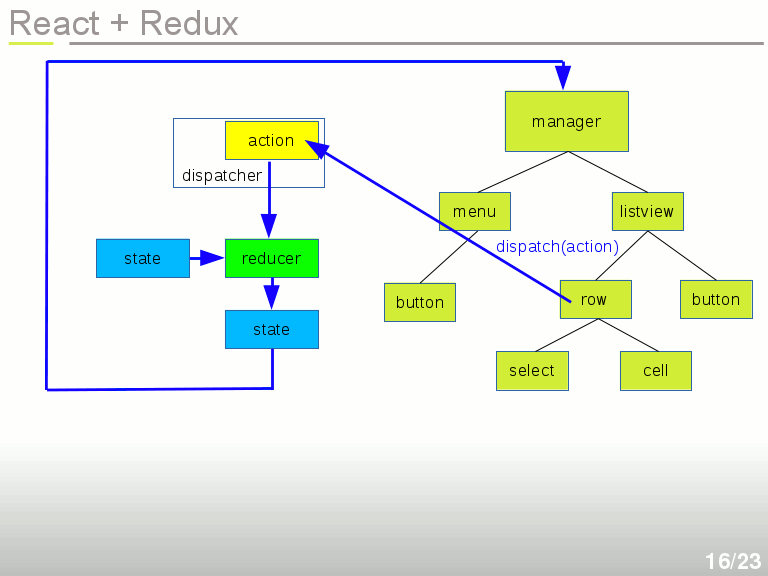
Une fois qu'on a calculé le nouvel état de notre application, on peut régénérer entièrement le DOM virtuel, puis l'envoyer à React pour affichage.
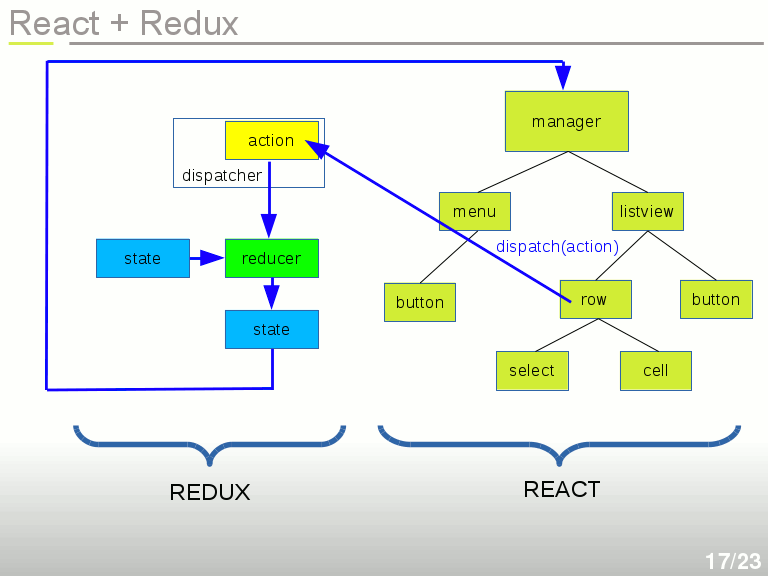
On voit dans le slide ci-dessous la répartition des rôles entre React et Redux, qui est bien distincte : React s'occupe de la partie DOM virtuel uniquement, et Redux s'occupe de gérer les actions et l'état de notre application. Pour faire la comparaison avec le modèle MVC, on pourrait dire que React correspond au V, et Redux correspond à M + C. Mais la dépendance à Redux est très faible, le State et les Reducers sont des fonctions en pur javascript sans aucune dépendance. C'est avant tout une question d'architecture.
Il est loin le temps où les applications devaient être « stateless », maintenant le but du jeu consiste à savoir gérer ce fameux State !
Un peu de code !
Maintenant un peu de code pour visualiser concrètement à quoi ça ressemble. Ci-dessous un composant React, le Manager en haut de l'arborescence. Cet objet contient un simple callback onRowSelection qui est lancé au clic sur une ligne. Et la fonction render() sert à renvoyer le bout de DOM virtuel, en utilisant la notation JSX (qui est totalement équivalente à un appel de React.CreateElement()).

Voici une version abrégée du State global de notre application, celui qui va être transformé par les Reducers. Il contient notamment la liste des lignes actuellement sélectionnées : selection : [1, 3, 7]

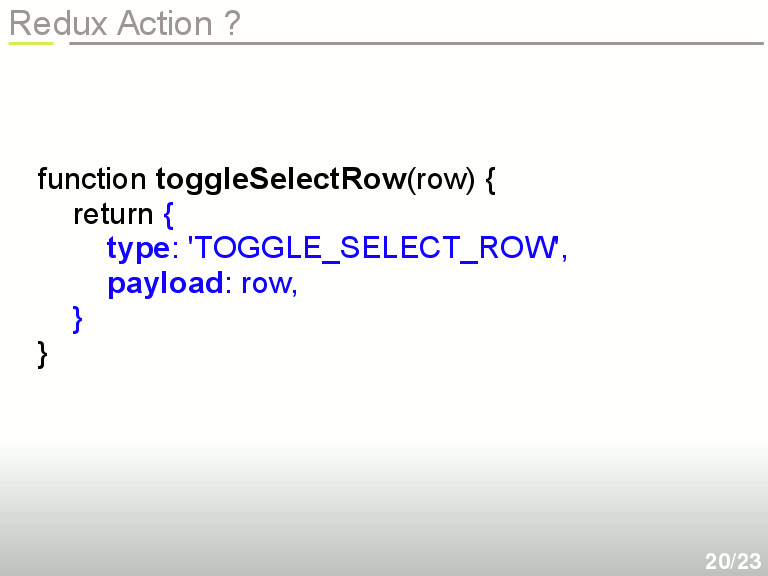
l'Action est un simple objet Javascript, qui donne le type d'action et des données supplémentaires éventuelles. On génère cet objet grâce à une fonction qu'on appelle Action Creator. Ici toggleSelectRow()
Finalement voici le Reducer. Comme prévu, il prend en argument le State (en réalité un sous-ensemble du State), ainsi que l'action. Puis il renvoie le nouveau State c'est à dire la nouvelle liste des lignes sélectionnées. Ce nouveau State sera ensuite utilisé dans le render() du composant racine pour recalculer tout le DOM virtuel.
Donc oui, avec React et Redux, sur une simple sélection de ligne, on recalcule TOUT ! On peut aussi faire ça dans un formulaire au moindre appui sur une touche. Ça paraît stupide, mais ça fonctionne et c'est rapide. C'est rapide parce que les fonctions sont pures, elles peuvent être mises en cache, les comparaisons sont légères et le traitement est globalement simple.

Voici donc de nouveau les trois principes de base de Redux :

Les avantages à ce système sont nombreux : c'est très facile à débugger, mieux que ça on peut faire du time-travel debugging : puisque les States sont en lecture seule, on peut les enregistrer à chaque action, et on peut facilement rejouer l'évolution chronologique de l'état de l'application, revenir en arrière, et retrouver la modification erronée. On peut aussi recharger à tout moment le code de l'application sans aucun impact sur son état actuel, sans avoir à rejouer les traitements depuis le début. On peut donc aussi démarrer l'application avec un State préalable (hydratation) et retrouver l'état exact d'une application sur demande. Parmi les autres avantages, on peut aussi mentionner la facilité d'implémenter des actions de undo/redo, puisque c'est natif. Et finalement, le code constitue en lui-même une documentation lisible : il suffit d'aller voir la liste des Actions dans le code pour avoir une visibilité sur la totalité de ce qui peut se passer dans l'application.

Conclusion
React est une vraie révolution au sens où il donne naissance à un nouveau paradigme de programmation web côté client. À l'instar de jQuery, on voit actuellement naitre une quantité énorme de composants React pour tout prendre en charge, depuis les animations jusqu'aux morceaux d'interface graphiques, des widgets, etc. Consultez par exemple la bibliothèque Material-UI, qui offre la plupart des widgets du Material Design de Google. Ou bien le composant de liste Griddle. On trouve même des outils de design d'interface graphique par drag'n'drop comme Structor. L'autre avantage de React, c'est qu'il a tendance à encourager la programmation fonctionnelle, qui est malheureusement si peu populaire, et Redux est un bel exemple de complément fonctionnel.
Cette architecture React + Redux n'est pas la seule possible, on en retrouve une dans Elm, sous une forme encore épurée et unifiée, intégrée dans un magnifique langage fonctionnel inspiré de Haskell, et qui contient sa propre implémentation de DOM virtuel. Si vous cherchez à éliminer 99% des bugs côté client et avoir une application extrêmement rapide (encore plus que React), et que vous n'avez pas peur d'un langage compilé à typage statique, alors allez voir Elm !
Je me prends parfois à rêver d'un ERP écrit en Haskell côté back et en Elm côté front...
Les slides au format ODP de cette présentation sont disponibles sous licence CC By Sa 3.0 ici: