
Introduction au Machine Learning avec Python
Le machine learning est un type d'intelligence artificielle (IA) qui donne aux ordinateurs la possibilité d'apprendre. Il se concentre sur le développement de programmes informatiques qui peuvent s'adapter lorsqu'ils sont exposés à de nouvelles données. Dans cet article, nous verrons les bases du machine learning puis dans un second la mise en place d'un projet réel avec Python et Scikit-learn.
Il s'agit de l'une des technologies les plus influentes et les plus puissantes dans le monde d'aujourd'hui et il ne fait aucun doute qu'elle continuera à faire la une des sujets d'innovations. Nous interagissons déjà avec le machine learning tous les jours. Chaque fois que nous cherchons quelque chose sur Google, que nous écoutons une chanson ou que nous prenons une photo, l'apprentissage automatique devient un élément du moteur, qui apprend et s'améliore constamment à chaque interaction. Il est également à l'origine de progrès qui changent le monde, comme la détection du cancer, la création de nouveaux médicaments et la conduite automatique des voitures.
Un peu d'histoire
L'histoire de l'intelligence artificielle ne débute pas hier mais prend racine il y a de ça plusieurs centaines d'années avec les réflexions des philosophes notamment. Il existe sur Wikipedia un excellent article sur l'histoire de l'intelligence artificielle qui reprend les pensées et grandes dates ayant contribué à son développement. Quelques dates sont toutefois plus importantes et méritent d'être mises en avant:
- 1950 - Alan Turing crée le "test de Turing" pour déterminer si un ordinateur a une réelle intelligence. Pour réussir le test, un ordinateur doit être capable de tromper un humain en lui faisant croire qu'il est aussi humain.
- 1952 - Arthur Samuel a écrit le premier programme de machine learning. Le programme était le jeu de dames, et l'ordinateur IBM s'améliorait au fur et à mesure qu'il jouait, étudiant les coups qui constituaient les stratégies gagnantes et incorporant ces coups dans son programme.
- 1957 - Frank Rosenblatt conçoit le premier réseau neuronal pour ordinateurs qui simule les processus de pensée du cerveau humain.
- 1967 - L'algorithme du "plus proche voisin" est écrit. Il permet de tracer un itinéraire pour les vendeurs itinérants, en commençant par une ville au hasard mais en s'assurant qu'ils visitent toutes les villes au cours d'une courte tournée.
- 1979 - Des étudiants de l'université de Stanford inventent le "Stanford Cart" qui peut naviguer seul dans les obstacles d'une pièce.
- Années 90 - Les travaux sur l'apprentissage machine passent d'une approche fondée sur la connaissance à une approche fondée sur les données. Les scientifiques commencent à créer des programmes pour les ordinateurs afin d'analyser de grandes quantités de données et de tirer des conclusions - ou "apprendre" - à partir des résultats.
- 1997 - Deep Blue d'IBM bat le champion du monde aux échecs.
- 2010 - Le Microsoft Kinect peut suivre 20 caractéristiques humaines à un rythme de 30 fois par seconde, permettant aux personnes d'interagir avec l'ordinateur par des mouvements et des gestes.
- 2011 - Google Brain est développé et peut apprendre à découvrir et à catégoriser les objets un peu comme le fait un chat grâce au Deep Learning.
Depuis, les innovations s'enchainent, poussées par de grands acteurs comme Google ou Amazon et alimentent un débat autour des risques de cet apprentissage automatisé. Plusieurs milliers de chercheurs en IA et en robotique, soutenus par Stephen Hawking, Elon Musk et Steve Wozniak signent une lettre ouverte mettant en garde contre le danger des armes autonomes qui sélectionnent et engagent des cibles sans intervention humaine.
Types d'algorithmes
On considère qu'il existe 3 grandes familles d'algorithmes utilisés en machine learning:
Apprentissage supervisé
Il est appelé apprentissage supervisé parce que le processus d'apprentissage d'un algorithme à partir de l'ensemble des données. Le parallèle peut être fait avec un enseignant et ses élèves. Les bonnes réponses sont connues et l'algorithme fait itérativement des prédictions sur les données de formation et est corrigé par l'enseignant. L'apprentissage s'arrête lorsque l'algorithme atteint un niveau de performance acceptable.
Exemple : Vous disposez d'une série d'éléments que vous avez à classer. Vous connaissez ces éléments ainsi que leurs caractéristiques (taille, poids, odeur, couleur, forme ...) Parce que vous avez déjà fait l'exercice, vous fournissez vos jeux de données et de réponses à l'algorithme. Par la suite, à chaque ajout de nouveaux éléments, l'algorithme sera en mesure de les prendre en compte dans la classification.
Apprentissage non supervisé
Contrairement à l'apprentissage supervisé, il n'y a pas de réponses correctes et il n'y a pas non plus d'enseignant. Les algorithmes sont livrés à eux-mêmes pour découvrir et présenter la structure intéressante des données.
Exemple: Vous avez à classer des éléments dont nous ne connaissez aucune propriété. Vous n'avez donc aucun jeu de données ni solution à proposer à l'algorithme, celui-ci doit apprendre par lui-même.
Apprentissage par renforcement
Dans ce contexte, il s'agit de prendre des mesures appropriées pour maximiser la récompense dans une situation particulière. L'apprentissage en renforcement diffère de l'apprentissage supervisé dans la mesure où, dans ce dernier cas, les données de formation sont accompagnées de solutions, de sorte que le modèle est formé avec la bonne réponse. Dans l'apprentissage en renforcement, il n'y a pas de réponse mais l'agent de renforcement décide de ce qu'il doit faire pour accomplir la tâche donnée. En l'absence d'un ensemble de données de formation, il est tenu de tirer les leçons de son expérience.
Exemple: Un jeu d'échec.
Terminologie et processus
- Dataset : Un ensemble d'exemples de données, qui contiennent des caractéristiques importantes pour résoudre le problème.
- Caractéristiques : Des propriétés importantes qui nous aident à comprendre un problème. Elles sont introduites dans un algorithme pour l'aider à apprendre.
- Modèle : La représentation (modèle interne) d'un phénomène qu'un algorithme de machine learning a appris. Il l'apprend à partir des données qui lui sont présentées pendant la formation. Le modèle est la sortie que vous obtenez après avoir formé un algorithme. Par exemple, un algorithme d'arbre de décision serait formé et produirait un modèle d'arbre de décision.
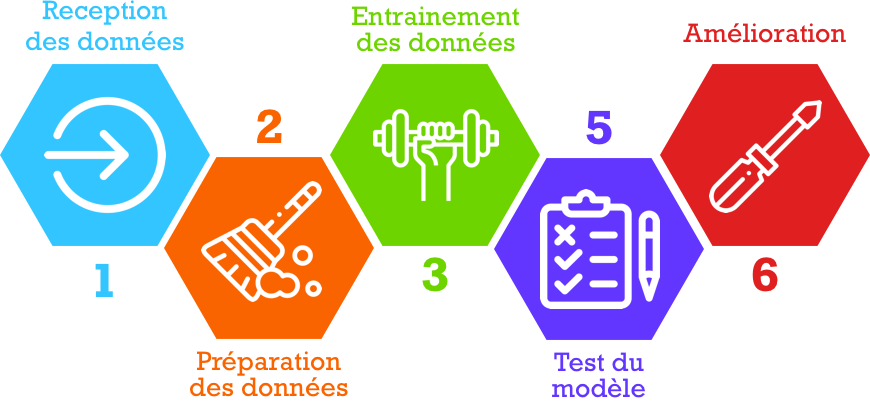
Le processus général du machine learning est le suivant:
- Collecte de données: Il s'agit de rassembler les données dont l'algorithme tirera des enseignements.
- Préparation des données: Celles-ci sont formatées en extrayant les caractéristiques importantes et en effectuant une réduction de dimension.
- Formation d'un modèle : Cette étape consiste à choisir l'algorithme approprié et la représentation des données sous la forme du modèle. Les données nettoyées sont divisées en deux parties : la première partie (données d'entraînement) sert à l'élaboration du modèle et la seconde partie (données d'essai) est utilisée pour l'entraînement. La seconde partie (données de test), sert de référence.
- Évaluation du modèle: Tester le modèle pour voir s'il fonctionne bien.
- Améliorer les performances: Ajuster le modèle pour maximiser ses performances.
C'est sur cette base théorique que nous pouvons passer à la partie pratique avec la mise en place d'un modèle de prédiction basé sur un apprentissage supervisé.




