
Comment débuter le Machine Learning avec Python et scikit-learn

Dans le précédent article, nous nous sommes concentrés sur la théorie pour définir ce qu'est le machine learning. Attachons-nous désormais à mettre en place un réel projet de machine learning et découvrir quelques possibilités offertes par scikit-learn.
La première chose à faire est de s'assurer que Python est bien installé. Si ce n'est pas le cas, Python est disponible sur l'ensemble des OS via le site officiel notamment. Une fois installé, nous n'aurons que peu de dépendances à savoir Pandas et scikit-learn. La commande pip install pandas scikit-learn permet d'installer ces deux bibliothèques.
Lorsque l'on débute le machine learning, il est coutume de commencer son apprentissage avec les Iris qui est un exemple de classification. De notre coté, nous partirons sur le même type d'exercice mais en utilisant des terminologies différentes. Plutôt que de travailler sur des Iris, nous allons utiliser des Contrats et ainsi déterminer quel contrat (d'assurance par exemple) correspond le mieux au profil soumis. Pour ce faire, je vous ai préparé un fichier csv avec les données que nous allons exploiter et la première chose à faire est bien entendu de le récupérer pour l'exploiter.
# load dataset
names = ["sex", "age", "weight", "children", "contract Name"]
dataset = read_csv("contracts.csv", names=names)
Vous pouvez désormais faire un petit tour sur vos données
print(dataset.head(20))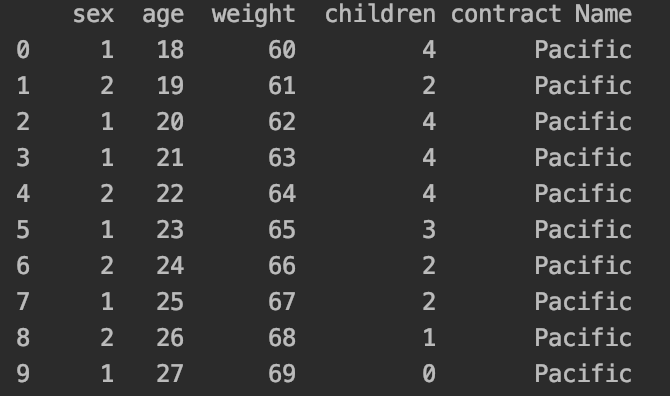
Choisir un modèle
Tout l'intérêt de notre exercice est de définir quel contrat correspond le mieux à une donnée précise. Pour cela, scikit-learn fournit tout un ensemble de modèles pour exploiter les données et nous ne savons pas encore lequel est le plus précis. Voici donc quelques lignes pour tester quelques uns de ces modèles et leur précision associée.
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))L'exécution de ces quelques lignes nous informe que c'est le modèle GaussianNB (Gaussian Naive Bayes) qui est le plus précis. Nous voilà donc avec notre modèle !
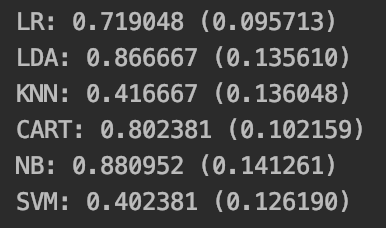
Place aux prédictions !
Tout l'intérêt de notre exercice est de pouvoir prédire le contrat qui sera associé à un profil soumis. C'est désormais quelque chose que nous allons pouvoir faire. Supposons que nous souhaitions connaitre le nom du contrat pour un homme de 27 ans, pesant 73kg avec un enfant. Il nous suffit alors de passer à notre modèle la demande de prédiction sous forme d'une liste
prediction = model.predict([[2, 27, 73, 1]])On observe ainsi que que c'est le contrat appelé "Pacific" qui est le plus adapté au profil de notre contractant. Mais qu'en est-il des autres contrats ? Quelles sont les probabilités associées ? Il est possible de faire appel à une méthode analogue predict_proba (doc) pour nous retourner ces informations.
predictions = model.predict_proba([[2, 27, 73, 1]])
for contract_name, accuracy in zip(model.classes_, predictions[0]):
print(contract_name, accuracy)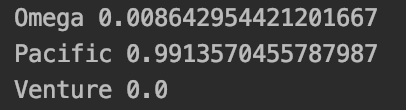
C'est sur cette prédiction que cet article se termine. Il avait pour objectif d'introduire quelques notions simples pour permettre aux novices d'écrire leurs premières lignes d'un projet d'intelligence artificielle. Il reste bien entendu énormément de choses et de concepts à découvrir et à approfondir pour mener à bien des projets de plus grande ampleur. La documentation officielle de scikit-learn représente un point de départ idéal en complément d'autres ressources comme machinelearningmastery.com. Bonne lecture !
from pandas import read_csv
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# 1 - Définition du Dataset
names = ["sex", "age", "weight", "children", "contract Name"]
dataset = read_csv("contracts.csv", sep=";", names=names)
# 2 - Entrainement du modèle
array = dataset.values
X = array[:,0:4]
y = array[:,4]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.25, random_state=1)
# 3 - Définition du modèle le plus adapté
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
model = GaussianNB()
model.fit(X_train, Y_train)
# 4 - Prédiction simple
prediction = model.predict([[2, 27, 73, 1]])
print("Predicted Value: %s" % prediction)
predictions = model.predict_proba([[2, 27, 73, 1]])
for contract_name, accuracy in zip(model.classes_, predictions[0]):
print(contract_name, accuracy)



